Electronic Data Publication in Geochemistry
Technical note published in G-cubed -- November 2002
Hubert Staudigel, John Helly, Anthony A.P. Koppers, Henry Shaw, William F. McDonough, Albrecht W. Hofmann, Charles H. Langmuir, Kerstin Lehnert, Baerbel Sarbas, Louis A. Derry and Alan Zindler
Download PDF of manuscript ...
Abstract
Many disciplines of geochemistry have no data reporting standards and their use of metadata is inadequately developed. This presents problems to the quality of the published science, and it limits the utility of computers in data analysis and the exploitation of Information Technology (IT). We discuss problems of data and metadata publication, in particular for geochemistry, and offer solutions to these problems in the form of consistent data publication formats and a proposal for publication of metadata in geochemistry. Metadata are grouped according to types (location, sampling, characterization) and this grouping allows for the transfer of these formats to other Earth science disciplines. In a companion paper (Helly et al., this volume) we illustrate how these metadata groupings can be used in an IT context. Formats presented here are comprehensive and allow for modification and expansion. It is the hope of the authors that this paper initiates a constructive discussion of data formats and metadata in geochemistry. The most recent contributions to this discussion may be found at http://earthref.org/metadata/GERM/.
Introduction
Geochemistry is still in the earliest stages of its exploitation of Information Technology (IT) as a tool for research, publication and data archiving. Nonetheless, it is clear that geochemistry, like most other Earth science disciplines, stands to reap substantial benefits from embracing IT. These benefits include wider dissemination of geochemical data, increased ease of use of data by different Earth science sub-disciplines, and more efficient storage and retrieval of archived data. Current common practices in the publication of geochemical data, however, present unnecessary obstacles to effective use of IT in geochemistry. These obstacles typically involve the lack of standardized formats for data and/or the omission of essential metadata (supplemental data that “describe” the “real” data). Common problems include:
These problems may be more prevalent in some disciplines in geochemistry than others, but they have a profound influence on how geochemistry functions as a scientific discipline. Inconsistency in data formats, and the lack of simple conversions between different normalizations set up unnecessary obstacles that are often difficult to overcome. This limits the extent to which data are accessible to researchers in other disciplines of Earth system science, and even to researchers in different subspecialties of geochemistry. These problems also make it unnecessarily arduous to meaningfully review the literature. As a result, geochemical data are much less efficiently used than they could be. Most importantly, many published data cannot be (re-)used because of the lack of critical metadata.
Some of the most important problems could be easily remedied if the community would embrace the electronic publication of data using a consistent standard with a minimum of mandatory metadata that are enforced in the review process of journal submissions. Metadata flagged as ”essential” in this paper are suggested as candidates for such mandatory metadata. The time is right for setting up such standards for data supplements. Most highly ranked journals have begun publication of electronic data supplements but their current use is minimal at best. Geochemistry, Geophysics, Geosystems is entirely electronic and has a substantial commitment to the efficient publication of data, as evidenced by the fact that one of its publication categories is entirely devoted to the publication of data. On the IT side, the development of data description languages, such as the Extensible Markup Language (XML) or metadata interchange formats (*.mif) are making it possible to “package” data into structures that are self-describing and can be automatically processed and used by any software that knows how to parse the description (see companion paper by Helly et al., this volume). Given this state of affairs, the major remaining obstacle to more effective electronic data storage, retrieval, and use in geochemistry is the definition of an appropriate minimum set of metadata. This should not be particularly difficult. In most cases, there is little ambiguity about which metadata need to be supplied in order to document geochemical data in a scholarly manner. The purpose of the metadata is to make the associated data maximally reproducible, searchable, easily usable, and comparable to other data in the same field. The main step remaining is putting these metadata in logical sequence and providing a format that can be easily read by humans and by computers. In this paper we propose such a data/metadata format for electronic data supplements. These supplements may be used in parallel with the typeset data tables in a paper or (ultimately) replace them. We focus here on solid (mostly geological) sample types, such as rocks and minerals, but we also apply this methodology to other types of geochemical samples, in particular fluids and gases.
Full disclosure of details regarding the samples, the sampling process and the analytical process is essential to a meaningful analysis of geochemical data. The current literature does not contain many examples with proper sample metadata — a habit that is often based on the size limitations of paper journals (see GERM Steering Committee, 2001). In the age of electronic dissemination of data, it is now possible to publish all data and metadata without the restrictions imposed by journal layout. This shift towards electronic data dissemination should be used to begin disclosing a critical minimum amount of information on all samples for which data are published in the peer-reviewed literature. The metadata scheme offered here contains a set of “essential” metadata for a scholarly sample description that would resolve most of the problems listed above. Nevertheless, we put this scheme together not as a unique and ultimate solution, but as a catalyst for a discussion on how the geochemical research community can most effectively take advantage of advances in Information Technology. A broadly accepted metadata standard may emerge after such a discussion.
Metadata Defined
The term “metadata” is relatively new to the language of the Earth sciences, and for this reason we wish to define the term both in general and in the sense we are using it in this document. Metadata are “data about data” and they can have different functions and contents. By function, we distinguish cataloguing metadata from application metadata. Cataloguing metadata includes any information that may be used in a card-catalogue to search for the existence of data. Dublin Core is one of the best established sets of cataloging metadata used, in particular, by the library community (http://dublincore.org/). Application metadata summarizes all information relevant to any particular science application. Such metadata come from the research archives of scientists and typically explain how data in question were produced and processed, including the nature and location of analyzed samples. They may include information that may be useful for the cataloguing of data including, for example, sample location, sample type or sample age. Here we focus on metadata with scientific contents.
Metadata may exist in the form of numeric or alphabetic entries such as key words, abbreviations, or a “controlled vocabulary” specific to a particular science discipline. Metadata can be expressed in written descriptions, in data tables, or in formats that are optimized for automated computer processing. In this paper, we focus on a tabulation of metadata in a form that is both comprehensible to humans and can be easily processed by computers.
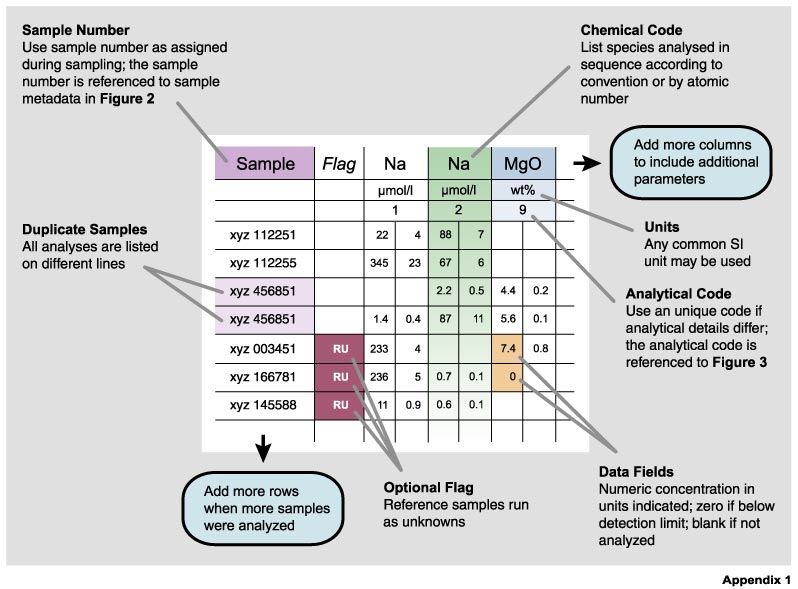
Figure 1. The main features of a geochemistry data table. Parameters are listed as columns and samples as rows. The first column gives the sample number which provides a link to the sample metadata in Figure 2. The first three rows give the parameters analyzed, reporting units and the analytical code for each parameter column. The analytical code links this particular analysis to the relevant metadata in Figure 3 explaining the analytical techniques. The sequence of elements should be listed either following a well-established convention or, preferably, by atomic number.
While it would be desirable to have extensive metadata available for every data point, it is clear that there must be some balance between the utility of the metadata and the effort required to collect and archive them. For this reason, it is important to find a minimum set of metadata that provides a reasonably complete description of the data, consistent with the goals of maximizing the utility and re-use of data. Furthermore, metadata formats must be flexible in order to accommodate the metadata needs of particular studies. In the metadata format discussed below, we have defined a minimum set of “essential” metadata that should be reported in any scholarly publication; all other metadata are considered important and useful, but optional. Each investigator is free to include additional new types of metadata, if a particular type of scientific contribution will benefit from their inclusion. This should accommodate the needs of specialist communities, and provide the potential for modifying the format so it can serve as a data input format for various databases.
The distinction of data and metadata can be confusing, whereby the same value or entry may be used in either way. For example, the latitude/longitude of a sample location may be used as metadata in a catalogue or as an archiving principle, or it may be used as data in a scientific analysis of sample properties as a function of regional distribution. We have grouped geochemical metadata in a modular framework that is transparent and applicable to different types of data and samples. Some of the metadata modules can be used for almost any geochemical sample type (e.g., sample identification, geographic location, sampling procedure, analytical procedure) while others are more specific to particular sample types. In the following text we explain the overall presentation of data and sample-related metadata with the use of illustrated examples. Specific formats for the description of geological, water and gas samples will be presented next to a common format for sample identification, geographic location and the sampling process. In all cases, these formats should be considered proposals intended to stimulate further discussion.
Data files
Electronic data supplements should be published as downloadable comma-delimited ASCII files that are not displayed as typeset data tables in the text version of a paper. Comma-delimited ASCII data files are universal and usable across any computer platform and software. They may be produced from spreadsheets (see the .csv format option in Excel), and read by all standard editors and easily read back into spreadsheet software relatively. Numeric data entries should not use commas but commas are ok in text strings (in a comma-delimited format text strings are marked by double quotes). In Figure 1 we have given a schematic example for such an electronic data file in tabular form (see Appendix 1 for examples). Data for particular samples are arranged in rows with data categories in columns. Each row is a separate data record with an unique sample identifier that is tied to the sample metadata table (Figure 2; Appendix 2). Each data column gives the chemical symbol for the parameter analyzed, the SI unit used, and an analytical code that is tied to a metadata description of analytical techniques as provided in a separate table (Figure 3; Appendix 3). As a result, data are linked to their metadata through the sample label in the first column and an analytical code that is given in the third field of each column.
Data files may have any number of columns, for all elements or isotope ratios analyzed. Data columns without data are not listed, and fields without data remain blank. Values that fall below the detection limit or below the calibrated range of an instrument should be given as “bdl”. It is preferable to have all the data in one table, rather than several separate tables. Multiple types of analyses of the same element in the same sample should be displayed in separate columns with separate analytical codes.
Multiple analyses of a given sample are displayed as separate lines (data records), but with identical sample labels. Analytical data on known reference samples are listed in the last rows of the data table. We encourage a consistent sequence of data columns. Such sequences should follow a broadly used “conventional” form. However, if there is no widely shared convention we recommend listing elements by atomic number. This sequence is universally recognizable, without knowledge of particular geochemical element characteristics, such as the exact sequence of relative compatibility of particular trace elements with a particular magmatic fractionation process. However, as long as data columns are clearly flagged, their sequence is clearly a second order problem in data publication. We illustrated some examples for data tables templates in Appendix 1. Common abbreviations used in these data tables can be found in Appendix 4.
Petrologists commonly report major element analyses as oxides using the assumption that cations in silicate rocks bond exclusively with oxygen and do not form any metallic bonds between them. This practice works well for most cations, except for Fe, which can display variable oxidation states. In this case, a choice has to be made for which oxidation state to use in its representation in a data column. We suggest here to use the one oxidation state that is likely to be dominant in a particular chemical system, but not to list FeO or Fe2O3 abundances based on the assumption of a fixed Fe2+/Fe3+ ratio. FeO and Fe2O3 abundances should be given only when the abundances for each valence states are determined analytically. If data are given as a bulk analysis, a “(t)” should be added to the chemical symbol to indicate that the total Fe inventory is represented in this particular form.
Sample-Related Metadata
We consider sample-related metadata for a range of commonly studied sample types from solids (including unconsolidated sediments) to fluids and gases. The sample-related metadata are illustrated in a summary diagram that lists all metadata types included in the rock, water and gas categories (Figure 2) and we present some examples in a spreadsheet environment (Appendix 2a,b,c). These metadata describe the sample location, the sampling method, and the sample itself while the analytical metadata (see Next Section; Figure 3) include information on the origin of the data, how the data were normalized, and the uncertainties of the data.
The metadata required for different kinds of geochemical samples vary even though the categories of metadata remain remarkably similar (Figure 2). Solids may include igneous, metamorphic or sedimentary rock types, minerals and fossils. But they can also be man-made such as experimental charges. Metadata fall into two logical groups, the first of which consists of information that is common to almost all sample types: sample identification, geographic data and sampling data. The second group of metadata consists of information that is unique to specific types of samples with respect to their sample description, classification or age. Many metadata categories provide for the names of scientists and references, in short citation form. Full addresses and references are given in separate address and reference files (Figure 3).
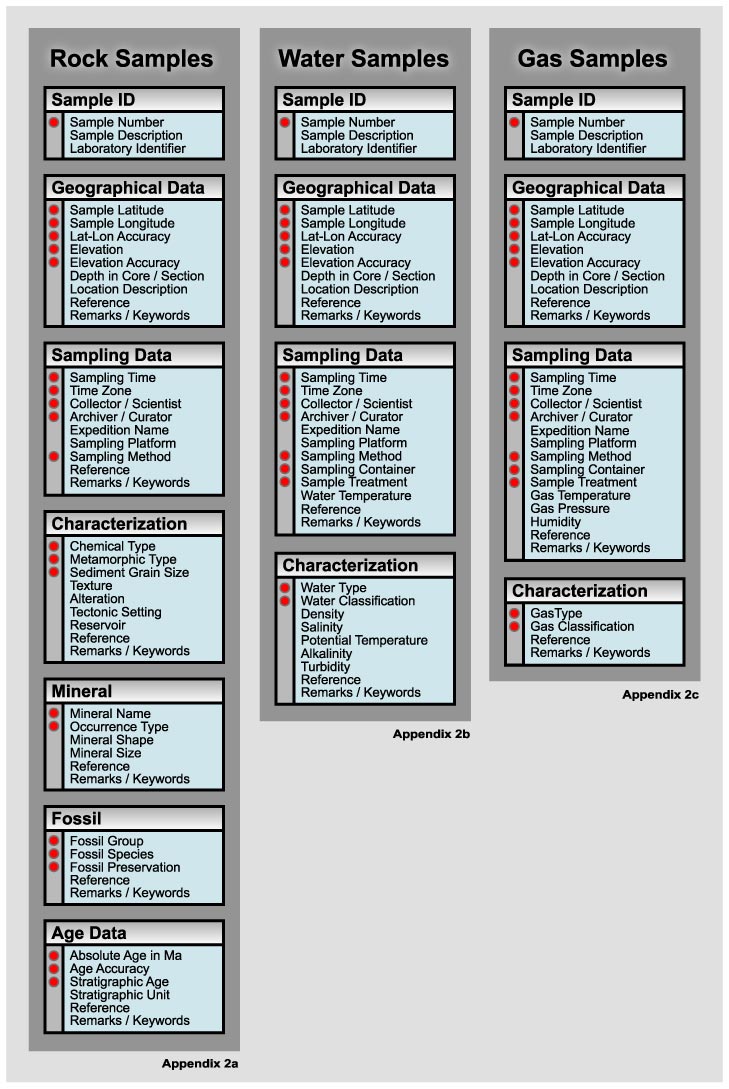
Figure 2. Metadata for sample descriptions for rocks, waters (fluids) and gases. Essential metadata are flagged with red dots and examples for these metadata descriptions can be found in Appendix 2 a-c. Note the similarity and consistency in metadata categories for Sample ID, Geographical Data and Sampling data for all sample types. See text and examples for detailed description of parameters.
The first metadata category is devoted to sample identification. The first entry in this category carries an alphanumeric sample identification (Figure 2). If there are several choices of sample numbers, the preferred choice should be the sample number that was assigned during the sampling process, because this relates to most of the other metadata provided here. The sample number is essential. A unique sample identifier can be derived from this number, combined with the location, sampling time and the scientist name. The second and third entry may be used for a short sample description and laboratory number, respectively.
Relevant geospatial information should to be given for all samples in decimal degrees latitude and longitude and meters elevation above mean sea level. Negative values indicate southern latitudes, western longitudes and depths. Uncertainties are given in the same units. An effort should be made to provide the most accurate latitude and longitude information possible since this numerical location estimate is most essential to any location description. Conservative uncertainties should be assigned that give a realistic estimate to which extent a location estimate can be trusted. In some earth science communities UTM coordinates may represent acceptable alternatives to latitude and longitude notation. We discourage their use because computer handling of global location information is greatly simplified in units of latitude and longitude. If UTM coordinates are given, the zone must be provided. Specific national reference grids in topographic sheets cannot be used instead of latitude and longitude, because they cannot be globally re-cast into latitude and longitude. They can be listed in an additional set of entries, if wanted. Location estimates may include a depth in a core or a land-section, but a reference has to be given to a description of the drill core or the profile taken. This reference may be an illustration in the same paper or in another publication. In addition, locations may be described by an appropriate geographic name (e.g., a mountain range, island, ocean basin, river, lake). Geographic names should avoid political terms if possible and be specific, but commonly known and identifiable in major geographic indexes. If there are commonly used English names for a mountain range or a country, the local name can be listed as well. A remark entry is added for any location related information, such as a description of the location, the sampling of a time-variant feature like an ash dusting collected after an eruption, an aerosol in an eruption cloud, or floodwater.
Sampling data (Figure 2) include information related to the sampling processes, including time, collector, archiver, methods, sampling platform, keywords on sampling and citations related to the sampling process. Such information is included in the metadata for two reasons: (1) to help with the interpretation of the data and to correlate samples from the same expedition or sampling method and (2) to assign uniform identifiers to samples that are analyzed by different laboratories and appear in different publications. The preferred format for the sampling time is decimal universal time (GMT) in the yyyy:mm:dd:hh.hh format. If for some reason local time is more appropriate (very rarely) the time zone must be specified remembering to consider daylight savings time. Sample time is considered essential for all samples because it is an important parameter for time-series sampling and because it helps assign a unique sample identifier for a particular sample. The precision of sampling time may be chosen as appropriate for the likely uses of the data; for a rock sample, simply the year might be sufficient to indicate a particular sampling season, while for a stream water sample time may need to be precise to the hour. The three following entries include information about the sampling platform (e.g., ship/vessel/airplane name) and expedition name, the scientist responsible for the sampling effort, and the scientist in charge of sample curation. These data allow the tracing of the data to other related data, an archival facility, or an investigator to whom sample requests could be directed. For water samples, there are additional entries on the sample treatment during sampling, including filtration, biocides, acidification, the temperature of the water sample, and the sample container. Obviously, not all of these categories will apply to all samples and inapplicable categories may be omitted. The sampling methods may provide important information with respect to potential sources of sampling related blank problems (e.g., diamond drilling vs. hammer sampling; Niskin bottle vs. Ti-syringe; squeeze extraction of pore waters; filtration of particles). A citation entry can be used for published or web-available publications on the sampling method used. Remarks may give more details on the sampling.
Some of the above data may not be recoverable for data publications on samples that were taken in the past or with less than ideal field characterizations. In those cases, metadata should be estimated if possible (e.g., latitude and longitude from “pre-GPS” field surveys), but they should not be listed if they cannot be reconstructed with confidence.
Sample Characterizations for Rocks
Rocks are defined here as any geological specimen. These include igneous, metamorphic and sedimentary rocks, unconsolidated sediments, meteorites, and even experimental charges. In this scheme, rocks may be characterized based on chemistry, metamorphic grade, grain size, texture, and in terms of their “setting”. The emphasis of descriptors in this metadata category should be the utility in a search for key rock groups, and not the need for classification in a specialist database. The main descriptor for rocks should be based on its chemistry/mineralogy, even if it is based only on a rough visual inspection. Even very rough terms such “basalt” (sensu lato, for any mafic extrusive) are acceptable, but it is better to use a more specific general term (hawaiite, picrite). Metamorphic and sedimentary rocks should also be primarily characterized using a term that includes the chemical composition but also by metamorphic grade and grain size characteristics, respectively. Any term that may be found in a general textbook may be used. Specialist classifications should be reserved for the “remarks” entry. Additional entries provide room for the description of igneous, metamorphic or sedimentary textures, and alteration. Alteration descriptions may include a general term for a low temperature alteration overprint, a percent estimate of the fraction of minerals replaced, or high temperature hydrothermal overprint. Tectonic setting or “reservoir” are keywords for whether a particular sample is relevant to the study of particular tectonic settings (mid-ocean ridges, arcs, continents) or particular geochemical reservoirs (core, mantle, continental crust). Multiple terms may be used if necessary. The purpose of these keywords is to help relating samples to a particular geological context, rather than assigning a particular reservoir or tectonic setting. Citations may be used for further descriptions of the rock type, and remarks may include specialist rock type descriptors, text descriptions of the sample or the relationship to a particular project.
For mineral or fossil samples an additional category is added to the metadata. The mineral characterization include essential descriptors such as mineral name and the type of occurrence (e.g., vein filling, groundmass phase, phenocryst, or xenocryst). Additional entries may be used to describe mineral shape (euhedral/anhedral), the size, and a citation and remarks.
For fossils, essential descriptors include genus, species and preservation. Any common type of preservation index is acceptable, based on color, or based on extent of mineral (aragonite) replacement. In addition, there are entries for a citation and remarks or text descriptions.
Rocks must also be characterized with respect to their age. This information is essential. The age may be given as an absolute age (with uncertainty), as a bio/magneto stratigraphic age, or both. An optional entry offers the opportunity to give a local stratigraphic unit. Every age has to be supported either with a reference (or some explanatory text) that allows judgment of the quality of the age data. In many cases, the age is well known and can be assigned based on high-precision geochronological data. However, even if the age is known only very roughly (such as 22±20 Ma), such an age is still useful in searches over broad geological time periods.
Sample Characterization for Water Samples
Water samples have similar metadata types for sample identification, geographic data and sampling data as geological samples (see descriptions above; Figure 2). In addition to geographic coordinates, sampling date, and physical properties such as temperature, river metadata should include discharge and suspended sediment information when possible. These can be added in a separate entry to the geographic data. Sampling data for waters should include filtration (type and size), acidification, biocides and temperature of sampling. Water samples are characterized with respect to water type (hydrothermal water, ground water, pore water, seawater, precipitation, lake, river water, etc.) and a water classification that gives a more specific (or additional) description (e.g. black smoker, bottom water, North Atlantic Deep Water). Water samples are also characterized with a variety of physical and chemical properties (hydrographic data), including pressure, potential temperature, density, and particulate contents (Nephelometer readings). Hydrographic data standards for seawater are well established, such as for the World Ocean Circulation Experiment (“WOCE”; Swift and Diggs, 2001; http://whpo.ucsd.edu/exchange/exchange_format_desc.htm). Such previous recommendations should be followed to a maximum extent possible, even though some re-organization in groupings may be beneficial in many cases. However, most other geochemical disciplines in water chemistry do not have the same level of organization as in oceanography and standards vary widely in the types of data and metadata reported. In absence of well described specific standards, we recommend establishment of standards along the lines of the description presented here.
Sample Characterization for Gas Samples
Location estimates and much of the sampling metadata are similar to waters and rocks. Specific gas related sampling metadata include the sampling method, type of container, filtration, sampling pressure, temperature and humidity. Sample characterization includes a gas type for the general classification (natural gas, air, hydrothermal) and a gas characterization for the more specialized classification (plume, solfatara).
Exceptions
There are data generation/collection efforts in geochemistry and cosmochemistry that do not fit into the above scheme. For example, meteorites are not usefully referenceable in a geospatial reference frame, and averaged data may integrate over a very large, even global, scale. In these cases, only some of the sample metadata categories will apply and other metadata may be omitted from this scheme.
Analytical Details
Each geochemical parameter in a data column of Figure 1 is associated with an analytical code that links to analytical metadata in Figure 3. Examples for analytical metadata files are given in Appendix 3. These metadata provide information on the type of analytical techniques used, the origin of the data, how samples are processed in the laboratory, how the parameters are represented, how they were determined, their uncertainties, and blanks. These data serve two main purposes: (1) to allow a data base user to evaluate the analytical work, and (2) to provide guidance on the use of the data. Most of the analytical metadata should be considered essential, at least, all the information that is needed to recalculate data into a different notation or to reproduce a particular method of sample processing or analysis.
The first metadata entry contains the analytical code given for each element in the main data table. The following entries in this section include the instrument type (using abbreviations listed in Appendix 4), the element or isotope (ratio) that this particular metadata set applies to and some general remarks about the technique. The next set of parameters includes information on the data origin, including the responsible analyst, the laboratory, the time of analysis, a citation regarding the laboratory and/or the analyst, and some remarks or keywords.
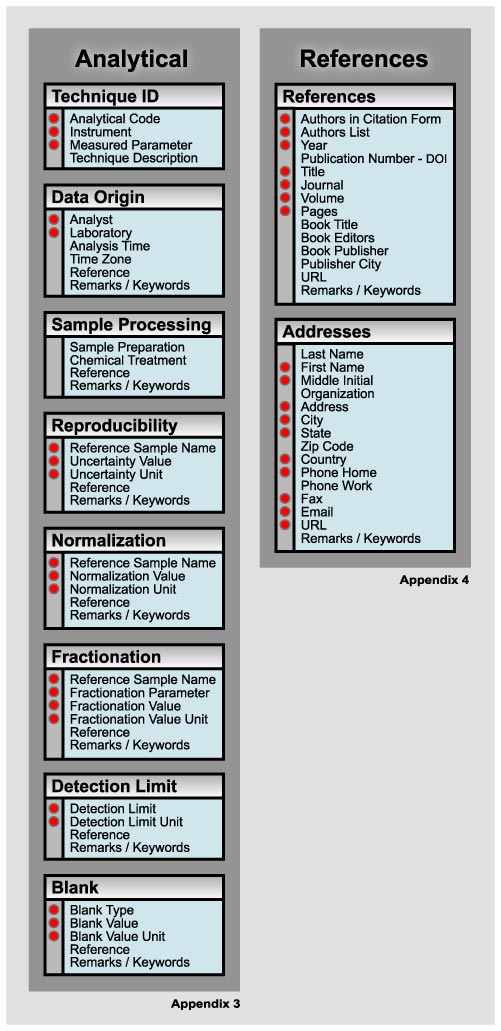
Figure 3. Metadata for analytical techniques, references and author/sampler/curator addresses. Essential metadata are flagged with red dots.
Sample processing contains information regarding sample preparation before analysis. The first entry describes sample preparation, including in particular comments that help understand potential contamination issues. The second entry describes chemical treatments such as leaching, or ion exchange, drying or firing before analysis, and a column for remarks regarding sample treatment.
The following section of analytical metadata is devoted to the reproducibility of the analysis for each geochemical parameter. Errors listed here should be exclusively “external” errors, that were determined on basis of repeat analysis of the reference samples. However, if internal errors are used (i.e. based on individual counting statistics for a particular sample) they should be given in the data table (Figure 1) as a separate column next to the respective column of analytical data.
The next section is devoted to describe sample normalizations. Here, all information is compiled that is needed to transform data into different common normalizations. There are a variety of relevant normalizations that are considered in this section. Data may be normalized to 100%, relative to some specific reference samples, or to instrumental fractionation, such as due to mass fractionation. The first entry gives the reference sample name, the reference value to which the samples are re-normalized. If data are normalized to 100% the original sums must be reported with the data in an additional data column so the absolute abundances can be retrieved for each element analysed. There are also entries for a fractionation parameter, such as the mass fractionation its value and unit. These entries must contain all information necessary to allow a reader to re-normalize the published data such they fit any other commonly used CI concentration unit (http://www.bipm.fr/enus/3_SI/base_units.html). All essential information has to be listed such that a “generalist” will be able to readily translate between different units used in geochemistry.
Detection limits and blanks must be given for all analyses whereby the detection limit should be defined as the lowest calibrated value of an instrument. Blanks are described with a value, type of blank and its unit. Acceptable types of blanks include, for example, cumulate reagent blanks and procedural blanks. All blanks must be given so they can be correlated with a typical analytical procedure for the data reported.
References and Addresses
In Figure 3 (Appendix 4), we have given a format for references that were used in the sample descriptions or analytical metadata, and for addresses as they may relate to personal references. For the references we have listed essential fields for the authors in citation form, authors, year, the Electronic Publication Indentifier (DOI), the title, journal, volume and pages. Whenever appropriate, we also include information on a book, URL or remarks. For address information, we listed a minimum number of data that are necessary to get in touch with a person to get additional information, obtain sample splits and so on.
Concluding Remarks
Any new comprehensive standardized format for data and metadata at first appears difficult and certainly labor intensive to implement. This is the case particularly for data that are were obtained prior to an agreement on standards. Problems include conversion of metadata into new formats and extraction of metadata from maps and laboratory field notes. Many metadata may have been never collected or may not be recoverable at this stage. This should not prohibit publication of data because it is still better to have data with imperfect metadata than no data. Once data standards are established, their use in new studies does not impose any significant obstacle or additional burden. In fact, standard metadata sheets will be helpful as a checklist for comprehensive note keeping and as a filing system for metadata information gathered in the course of a study. Many steps in metadata acquisition and archival may be automated using laboratory instruments or handheld GPS receivers. For many studies, many metadata columns can be filled wholesale because the parameters do not change for the entire sample suite analyzed. It is obvious that metadata collection can be tedious, but it is also quite clear that they are one of the most efficient and transparent ways to keep track of information that is essential for scholarly scientific studies.
We have compiled and organized geochemical data and metadata categories into a format that would allow effective publication of geochemical data in an electronic environment. We hope we have made the case that establishing such a format is an important step toward greatly improving data publication in geochemistry. We believe that adopting our formats will be a great step forward, while keeping the overall effort relatively small. Nevertheless, our key goal is not to impose a particular method of data publication but rather to contribute to the discussion of important technical publication issues. Resolution of these issues will have substantial impact on the scholarly quality of science publications and on the ease at which geochemistry will be able to take advantage of Information Technology. This paper is the result of discussions at the data base subgroup session at the GERM 2001 workshop at La Jolla, CA. Internet access to this paper and future contributions to this topic can be found at http://earthref.org/metadata/GERM/. Contributions or opinions to the metadata discussion are welcome.
Acknowledgements
We thank Bruce Deck for his gas metadata suggestions, and Rick Carlson and Marjorie Wilson for insightful reviews and the National Science Foundation for funding this work (EAR0000998, DUE-027684)