Scalable Models of Data Sharing in Earth Sciences
Technical note published in G-cubed -- November 2002
John Helly, Hubert Staudigel, and Anthony A.P. Koppers
Download PDF of manuscript ...
Abstract
Many Earth science disciplines are currently experiencing the emergence of new ways of data publication and the establishment of an information technology infrastructure for data archiving and exchange. Building on efforts to standardize data and metadata publication in geochemistry (Staudigel et al. 2003) we are discussing options for data publication, archiving and exchange. All of these options have to be structured to meet some minimum requirements of scholarly publication, in particular reliability of archival, reproducibility and falsifiability. All data publication and archival methods should strive to produce data bases that are fully interoperable which requires an appropriate data and metadata interchange protocol. To accomplish the latter we propose a new Metadata Interchange Format (.mif) that can be used for more effective sharing of data and metadata across digital libraries, data archives and research projects. This is not a proposal for a particular set of metadata parameters but rather of a methodology that will enable them to be easily developed and interchanged between research organizations. Examples are provided for geochemical data as well as map images to illustrate the flexibility of the approach.
Introduction
Most data and metadata in Earth sciences are published in the context of traditional, peer-reviewed publications in paper journals. The practice of publishing data electronically is extremely poorly developed, in particular, since electronic journals continue to be functionally similar to paper journals. The confinement of most data publication to paper journals has the result that authors rarely publish data and even less frequently their metadata (Helly 1998). In geochemistry, this has resulted in a crisis in data publications (GERM Steering Committee, 2001) where a large amount of legacy data are in danger of being permanently “buried” in private research files (see Figure 1a). Earth sciences are likely to gain substantially from introducing new means of publishing data. There is a wide array of electronic data publications that range from strict peer-reviewed, central publication to entirely non-reviewed, decentralized publication on personal websites (Table 1).
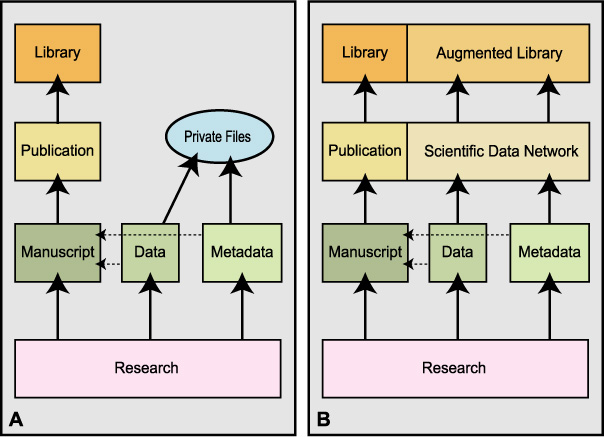
Research produces effectively three types of data products: (1) data, (2) metadata and (3) the interpretations of these data in the form of various illustrations included in manuscripts. Our current paper publishing protocol (Figure 1a) is mostly biased towards the final writing and illustrations. Digital data and metadata tend to be rarely published on paper copy or in its electronic equivalents (dashed lines). Page limitations in high profile journals actively work to eliminate or greatly reduce the actual publication of data and metadata. As a result, interpretations and figures based on data are widely published and archived in libraries, while most of the primary data are confined to research files of investigators. These private archives, however, do not provide sufficient access for future research that might result in a re-interpretation of the data. There exists no return flow of data into community-wide research activities and, therefore, these data are effectively lost. In the worst possible case, samples will have to be re-analyzed, forcing another cycle of data generation and loss. This puts Earth sciences in a situation where the transient interpretations of data are kept in reliable archives while the actual permanent measurements and records have an uncertain fate. This effective loss of data or metadata due to non-publication cannot be reconciled with our principles of scholarly science. Without them, scientific work cannot be duplicated or falsified.
In Figure 1b, we show an alternate data publication protocol in which the generation of scientific products and its publication remains the same, but data and metadata are published in a scientific data network. This network takes on the role of libraries for the archiving and serving of data to the scientific community in order to support future research. In this new protocol the traditional publication of scientific results is accompanied by publication of its data and metadata making the “complete” scientific product available in a consistent and coherent manner (Helly et al., 2000; 2002). Such a data network may include a range of options, including the attachment of electronic data supplements to publications (GERM Steering Committee, 2001).
Figure 1a. Schematic depiction of the flow of scientific information from research to published library resources as currently practiced. Figure 1b. Potential approach based on interoperable resources contained within a scientific data network but leading to library-grade products analogous to the formally published journals we are familiar with today. This augmented library will protect the future of science against any loss of valuable research data that normally resides in private files. Note that the dashed lines from data and metadata to the manuscript reflect the limited publication of these information sources in our conventional manuscripts.
Electronic data publication in Earth sciences is still in an emerging phase, where many options may be considered that have particular advantages to particular Earth science communities. Metadata play an important role in such data networks, but as different Earth science disciplines may choose different data publishing protocols, it becomes extremely important to have data and metadata in representations that are interchangeable between protocols, standards and conventions. These features are referred to as interoperability and platform-independence.
In this paper we will discuss different methods of data publishing via a scientific data network, the desirable characteristics required to make such a network into a truly scholarly resource, and we will introduce a method for generating a highly portable metadata interchange format we call .mif (pronounced dot-mif) that will help make an Earth science data network interoperable. This .mif format is designed to help search, extract and exchange data and metadata as they might be stored in a range of personal or community Earth science archives. We will conclude this paper with a discussion of how this metadata format can be scaled to support the diversity of interests within earth science communities. This paper is part of a discussion on metadata and data archiving infrastructures, and the most recent contributions to this discussion may be found at http://Earthref.org/metadata/GERM/.
Methods of Data Publishing
Geochemical and earth science data may be published in a variety of ways. IT offers a range of publication options that may be classified by their respective publishing protocols and their system architecture. In Table 1 we have illustrated various publication protocols using these two parameters. The choices between these protocols are mainly driven by the technical issues relating to centralization, peer-review procedures, the complexity of data, the cost of publication and archival requirements. However, some of the most difficult choices often involve socio-political issues, such as which groups or organizations are interested in operating a data network whether centralized or de-centralized. These choices are difficult because they usually have to be made competitively where the winner is expected to deliver the best product for the community, in exchange for funding and scientific benefits. A careful evaluation is needed to balance the benefits of the freedom of managing one’s own data versus the responsibilities and costs of maintaining a large number of public data servers that are also reliable.
The classical model of scholarly publishing is the scientific journal with a protocol based on peer-review and editorial boards. The architecture supporting this is a centralized one typically located at the publisher’s facilities where the copyright and copy-of-record are retained. In the past, libraries were also keepers of the copy-of-record and the redundancy of libraries provided insurance that there would “always” be a copy available. Now, with the shift to e-publishing, it is the publishers who hold the copy-of-record and the libraries themselves never actually hold anything. Subscriptions to electronic journals gives temporary access to contents, not ownership of an archive. At the other end of the spectrum of centralization is a completely de-centralized system architecture united only by the basic http protocol is exemplified by individual web-sites without any publishing protocol per se; what you see is what you get and it may not be there tomorrow.
As an intermediate case, federated networks may be thought of as de-centralized but locally structured and operated according to shared, community-defined protocols and standards. A particularly interesting and recent example is the music distribution network approach of Kazaa at http://www.kazaa.com. Kazaa uses a peer-to-peer approach but selects a subset of peers to also act as search-server nodes according to their exceptional computational and communication resources. This has the particular advantage of federating the server function that supports searching (based on the metadata of song, artist and peer-node) without centralizing it. This approach is also capable of dynamically reconstituting the subset of servers if one or more is removed from the network for any reason. Consequently, it is referred to as a self-organizing network
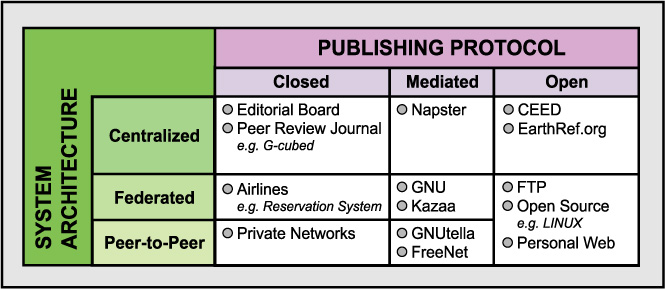
Table 1. Trade-off between system architecture and publishing protocol providing possible models of data publishing and sharing.
In the Earth sciences, disciplinary boundaries will naturally define important nodes in a scientific data network with discipline-specific publishing protocols and conventions. It could be operated as a self-organizing network (such as Kazaa) given sufficient standardization of both the data and metadata formats (see also Staudigel et al., this volume). Later in this paper we describe a new approach to metadata standards that could serve as a further step towards such a self-organized network. These protocols and conventions must provide local structure for the operation of the scientific data network while supporting the diversity that is the very heart of specific Earth science research. Such protocols and conventions would include metadata standards, conventions for naming arbitrary data objects (ADO) so they can be uniquely cited and versioned (to enable verification/falsification) and conventions for protecting intellectual property rights. However, to clarify this notion we consider next the features that a scientific data network should have in order to effectively support scientific research in the future. As Earth science disciplines evolve their data management approaches, many options are possible. Key to any approach, however, is a design that supports scholarly work, and an effective data exchange mechanism.
Desirable Characteristics of A Scientific Data Network
Any scientific data network has to be designed to serve some basic principles of scholarly publication. One of the most fundamental requirements is the verification and falsification of results. Any analysis in science has to be accompanied by its data and metadata foundation during the process of the analysis, but also during its publication and archival. This dictum demands reliable access to published data and the ability to unambiguously identify the data used in any given analysis. To support these requirements, we have reproduced a table of essential functions needed in a data publication system (Table 2). These functions should be explicitly addressed in any system architecture in order to preserve all scientific data and metadata, regardless of the degree of its centralization.
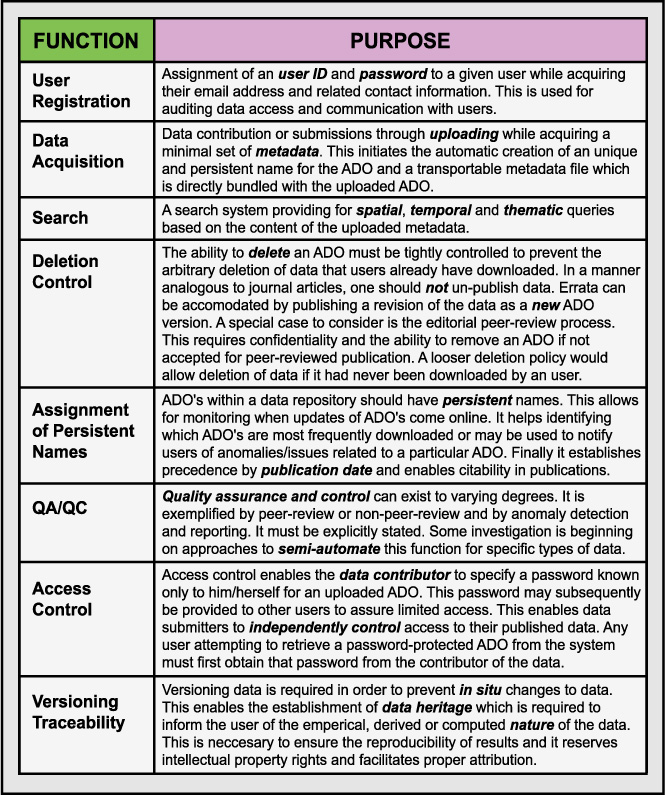
Table 2. Basic Functions for controlled publication of scientific data after Helly et al. (2002). ADO refers to an Arbitrary Digital Object which is a general term to describe any digital object; general a file of some kind, that can be stored in a computer file system. As the name implies, it may contain anything that can be digitally encoded.
In addition to these functions, we must consider reliability and availability of such a data network to ensure ready and repeatable access. These system engineering concerns are frequently overlooked in discussions about scientific publishing whether for data or scientific manuscripts. Reliability and availability of these electronic resources are vital with respect to the conduct of science and the equitable access to data throughout the research community. The software community has achieved this, albeit imperfectly, by a high degree of redundancy through the use of mirror sites for software, and a painstaking emphasis on clearly articulating the software version and hardware dependencies directly in the name of a software distribution file. Similar efforts of redundancy may be a key to the longevity of Earth science data and metadata archival and effective data exchange between interoperable data bases is essential.
Designing Metadata for Data Sharing
Metadata are essential to a successful data sharing, but the term can be very confusing. Metadata is many things to many people (Baru; Michener, Brunt et al. 1997; 1998; Daniel and Lagoze 1998; Federal Geographic Data Committee 1998; http://www.fgdc.gov/metadata/contstan.html 1998; PURL 1998; Weibel 1998). Our focus here is on key functions of metadata that are relevant to research and data exchange in the Earth sciences. Two main types of metadata may be distinguished. First, metadata is used for discovering the existence of data by searching a metadata catalogue or its equivalent. Second, metadata is documentary information describing the content, context, quality, structure, accessibility and so on of a specific data set.
In this latter respect metadata plays a role in the integration of data, analysis and modeling. In this paper we, therefore, refer to metadata either as cataloguing metadata (i.e. used for searching and archiving) or application metadata (i.e. used for data integration and scientific analysis). The key to these distinctions between data and metadata is how the information is used. Frequently, any particular parameter may be used in either way depending on the user’s purpose. For example the geographic latitude may be considered as data in the context of a correlation of rain isotope data with latitude, or it may be considered to be catalogue metadata when it is used to populate and search a metadata catalogue for papers relevant to particular regions. In another context, it may be considered application metadata when it is used as a variable in data analysis. Application metadata describing analytical methods (such as Appendix 2a-d, in Staudigel et al., 2002) may also be treated as data when they are shared between databases. Once shared, these same data may be used as both catalogue metadata to locate samples analyzed by a particular method as well as application metadata to support a data integration process merging samples analyzed by different methods and requiring a conversion of units.
Consequently, discussions on metadata can be confusing, subjective and discouraging. To make any progress on this front one seeks a systematic way to approach the definition of a reasonable set of metadata parameters. We begin this by recognizing that metadata is fundamentally arbitrary in nature. What’s important to one individual may be of little consequence to another and who’s to say what is more important? However, there usually exist subsets of metadata that are clearly required for any scholarly publication and more or less effortlessly agreed upon and that can be augmented to accommodate more specialized metadata requirements as they emerge. So we have designed an approach that accommodates this essential arbitrariness but enables compliance with whatever metadata standards or conventions emerge within the scientific, information technology, library and publishing communities. Some of the diversity of efforts that are relevant to the Earth science community, and that must be accommodated, is reflected in the list presented below:
Each of these approaches has strengths and weaknesses. For example, the Federal Geographic Data Committee (FGDC) standard was designed for geographic and remote sensing data and not for survey-type data, or laboratory data. It has subsequently been amended to a certain degree to make these accommodation and this emphasized the need to have a flexible convention that can evolve in response to disciplinary needs. It is clear is that there is a proliferation of metadata conventions that will continue to grow to accommodate particular purposes. It is, therefore, important to develop methods of interchanging metadata across these various conventions with ease and reliability to enable digital collections of data and digital libraries to interoperate making data more widely accessible.
In the design of metadata it is helpful to think in terms of data structures with well-understood mathematical and computational properties. One such data structure is a tree: a hierarchy with a root node, branches, sub-trees and leaves. Given categories of metadata, it is in some sense natural to organize them into a hierarchy or tree (Figure 2). Other data structures are possible and each has its own properties. However, a tree provides a modular structure that enables the addition and deletion of sub-trees of arbitrary depth and breadth without affecting other parts of the tree and this is well-suited to an evolving metadata architecture. For example, some sub-trees can be used for several Earth science disciplines without any adjustments because of commonalities in information requirements; such as the geographic data for sample location. A hierarchical structure also allows for the inclusion of other, well established metadata formats, such as the Dublin Core for bibliographic information that is used in almost any scientific effort (Figure 2). Each metadata parameter is a leaf attached to a branch of the tree and a path from the root to any leaf provides a complete and unique description of that metadata parameter. The same parameter name, for example latitude, may be used an arbitrary number of times as a leaf throughout the tree while each leaf is uniquely identifiable by the path through the tree to that particular use of latitude.
In Figure 2 we show a tree rooted to an unique identifier for the metadata interchange format (.mif) and including sub-trees for applications and catalogues (e.g., water analyses and the Dublin Core metadata standard). As we will show below this type of tree structure can be cast into a form that can be conveniently represented in a flat, ASCII-encoded, computer file.
Metadata Interchange Format
The main goal for our metadata interchange format (*.mif ) is to facilitate the automated electronic extraction and transfer of data and metadata from and between data bases as well as its accurate and effective re-use. The .mif convention allows a program to recognize the structure and contents of an electronic file. In our examples we use the spreadsheet compilations of data and metadata as they are described in the companion paper by Staudigel et al. (2002). These files are considered ADOs and the *.mif files describe these files in a way that allows a database to export its contents and to identify its contents and structure, so the tables can be uniquely imported (i.e., read, accurately reproduced and translated into other formats) by another data system. Such an export/import approach makes a database interoperable with others by facilitating automated access to its contents.
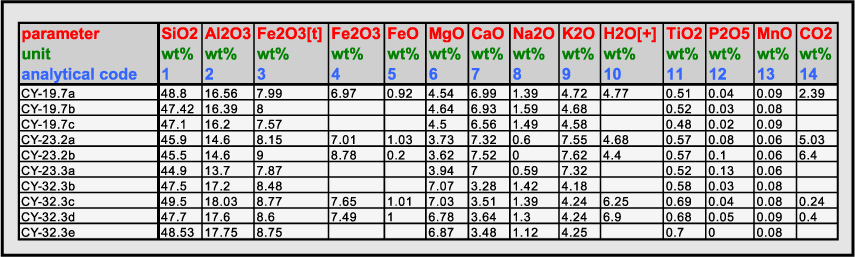
Example 1. Major Element Table from Staudigel et al, 2002.
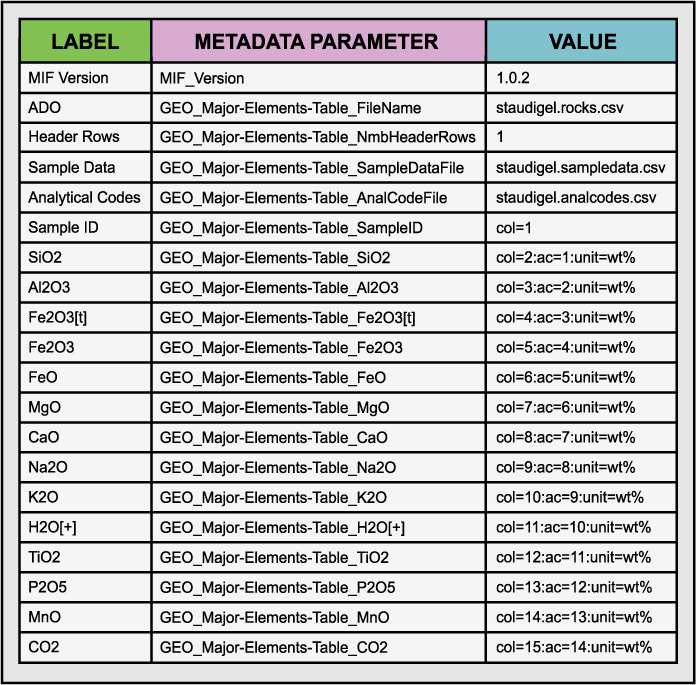
Table 3. Example of the metadata interchange format (*.mif) using the ROCK SAMPLE MAJOR ELEMENTS table from Staudigel et al (2002).
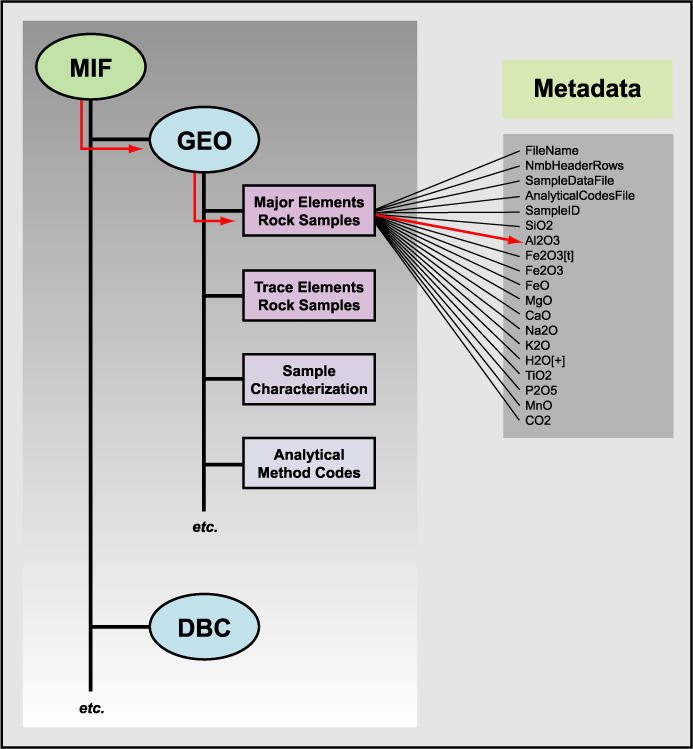
Figure 2. Example metadata tree. The root is at MIF and the leaves are at right. Red indicates path corresponding to *.mif record shown in Example 1. DBC corresponds to other non-GEO metadata content standards that might also be supported by the community such as Dublin Core.
In Table 3 we present an example of the *.mif format for the ROCK SAMPLE MAJOR ELEMENTS table from Staudigel et al (2002). The *.mif can be described as a series triples (i.e., three elements) that describe the headers of a data table. Each triplet consists of a human legible header (Label), a name for the metadata parameter, and a value. The label field provides a place to put a conventional, human-readable label that may contain special characters that are not well-suited to inclusion in metadata catalogues as searchable metadata (e.g., some special characters are used as delimiters in operating system commands and this can result in interference with programs with abnormal results) but that have special significance in the context of the data object itself. The parameter name is constructed so that it encodes the logical structure of the ADO and enables it to be accurately reconstructed and interpreted from the metadata content. The values field provides a set of metadata that can be stored in a catalogue to enable the ADO to be found and to provide cross-references to related ADOs containing information relevant to, in this case, the major element analyses as described in Appendix 3 of Staudigel et a., 2002. For example, among the metadata fields in Table 3 are also fields that specify the ADO containing the analytical code metadata (i.e., staudigel_analcodes.csv) and the positional information (i.e., staudigel_sampdata.csv). The latter information enables the major element table ADO to be discovered in a geospatially-based search. Alternatively, the geospatial information could be included in the metadata in Table 1. These are further examples of the use of data and metadata interchangeably as a function of the purpose they are used for. Each record of the corresponding comma-delimited, ASCII, row-oriented *.mif file would be formatted as shown in Example 2.
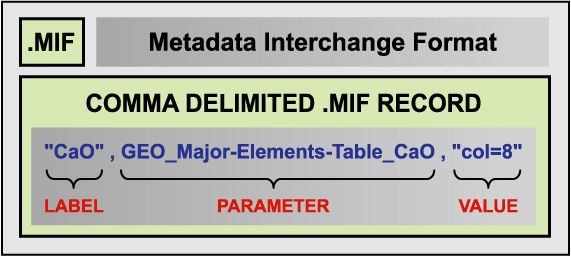
Example 2. A single metadata record in *.mif. Underscores separate levels of the hierarchy in this example and hyphens delimit words that would otherwise be separated by blank spaces. These conventions are used to ensure proper parsing for import and export.
Defining A Standard Set of Metadata Parameters
The .mif standard may evolve with time, or different data bases may employ different .mif structures. To allow for conversions between such versions or data base structures, the *.mif convention includes a metadata template file (*.mtf) describing a particular version of the interchange metadata format standard. The relevant science community can control the content of the *.mtf file through, for example, a working group by defining a standard set of parameters that are used as metadata for the various standard ADOs. This set can be as large as necessary but as small as is sufficient. There should be at least one metadata group or block per type of ADO. In our rock-sample-major-elements-table example above, this type of table is defined and published as a community-recognized type of digital object (i.e., ADO), the content of its associated metadata file (e.g., staudigel_rocks.mif) is published in accordance with the definition of metadata parameters contained in a published versions of a *.mtf (e.g., AGU_GEO.mtf) and researchers can freely exchange this type of object with its standard metadata in a simple and unambiguous way as illustrated in Figure 3.
The contents of an *.mtf file corresponding to the *.mif file structure shown in Table 3 are illustrated in Table 4. It is simply the same as the *.mif with some additional information about how to format the *.mif file from a programming point-of-view. We use the *.mtf file to configure metadata editors and control the import/export processing of *.mif versions. It is the authoritative definition of a given *.mif version and can be processed to produce *.mif files automatically. Note that the value <ADO Name> is used to indicate that that name of the appropriate ADO should be inserted for the value field in the *.mif file when it is produced. The *.mtf contains information sufficient to unambiguously read and write the contents of the *.mif file and it explicitly defines the structure and contents of the corresponding type of ADO. This is a representative set of parameters and should not be construed as limiting but it is sufficient to construct the appropriate *.mif file for our example.
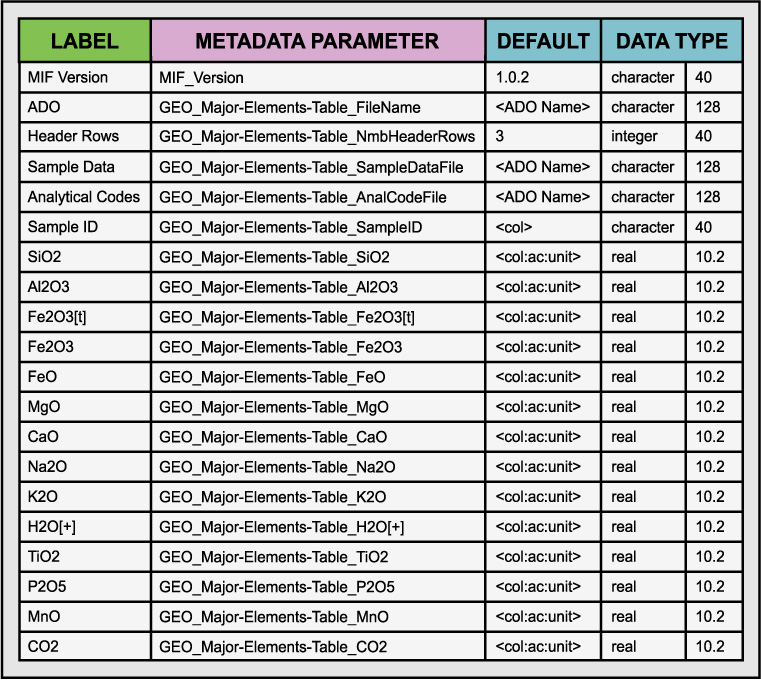
Table 4. Example Metadata Template File (*.mtf) contents
Figure 3. Depiction of the use of *.mtf files to define how the *.mif files should be written and read by the data exporter and data importer respectively. The *.mif file describes how to read and interpret the ADO (i.e., staudigel_rocks.csv). The *.mtf file contains a metadata block for the rock-sample-major-elements-table ADO and therefore defines how the *.mif file for the ADO should be written and therefore defines the structure of the ADO.
Import and export filters can be readily built to read or write such ADOs and *.mif files and, in this way, digital objects and associated metadata get published in a standard and useful way while retaining the flexibility to modify the structure under community control over time as the science requires.
Naming Conventions for ADOs and *.mif Files
So far in the example above we have used a simple file name as a prefix. In a practical system for interoperable data sharing, there must be a means of ensuring the unique naming of each pair of an ADO and its *.mif file. The reasons for unique naming includes in particular the citeability and traceability of parameters. We must be able to uniquely identify data used in analyses and be able to refer to specific and unambiguous data objects in our work. One convention we have used successfully in a number of applications is shown in the following example.

Example 3. Naming convention for an ADO (above) and the correspondingly named ADO, mif pair (below). Here underscores separate parts of the ADO filename and are not related to the hierarchy referred to in Example 2.
The creation datetime and the version datetime have the same value when the ADO and *.mif files are first created or published but subsequent versions of the data and metadata that may be issued for various reasons will update only the version date. In this way, the same basic ADO and *.mif files will sort together in a computer’s file system making it easy to find the most current version of an ADO and *.mif file as well as the entire historical record of that ADO. We have put igpp in the front of the name to identify the organization that produced (i.e., published) the data. This particular combination of codings enables the ADO to be uniquely named within the collection of digital objects within the IGPP as well as without. Properly done, a scientific data network should have a community-based group that ensures that each data publisher is assigned a unique identification. This can be relatively easily done by using the above convention and by assigning unique codes for all participants in the data network.
This approach is not limited to geochemistry data, nor to table data. For example, it is the metadata approach being used for the SIOExplorer project (http://sioexplorer.ucsd.edu). An additional example of the application of the *.mif approach is presented in Appendix A. This example illustrates the use of this approach to document raster images, especially maps, using the *.mif conventions.
Summary and Conclusions
The ability of investigators to share data is essential to the progress of interdisciplinary and integrative scientific research. This is true even within individual disciplines. Here we have described a range of information architectures for effecting differing levels of standardization and centralization. We have proposed a generic .mif metadata interchange format for use in the Earth sciences and potentially other disciplines and described how these can be created using a metadata interchange template file that is controlled by the community and used to define the various types of ADOs and there corresponding *.mif files. While using a highly-structured but openly-available metadata format we are able to achieve effective data sharing across digital libraries, data archives, libraries and research projects. The most recent contributions to this discussion and .mif applications and examples may be found at http://earthref.org/metadata/GERM/.
Literature Cited
Baru, C., R. Frost, R. Marciano, R. Moore, A. Rajasekar, M. Wan (1997). Metadata to Support Information-Based Computing Environments. IEEE International Conference on MetaData 97
Daniel, R. and C. Lagoze (1998). Extending the Warwick Framework: From Metadata Containers to Active Digital Objects. http://www.dlib.org/dlib/november97/daniel/11daniel.html : 1-13.
Federal Geographic Data Committee, M. A. H. W. G. (1998). Content Standard for Digital Geospatial Metadata. Reston, Virginia, U. S. Geological Survey. http://www.fgdc.gov/metadata/contstan.html (1998).
Helly, J.; Elvins, T.T.; Sutton, D.; Martinez, D.; Miller, S; Pickett, S.; Ellison, A. M., (2002) Controlled Publication of Digital Scientific Data. CACM (May, 2002).
Helly, J., Elvins, T. Todd; Sutton, D; Martinez, D (1999). A Method for Interoperable Digital Libraries and Data Repositories, Future Generation Computer Systems, Elsevier 16(1): 21-28.
Helly, J. (1998). "New concepts of publication." Nature 393: 107.
Michener, W. K., J. W. Brunt, et al. (1997). "Nongeospatial Metadata for the Ecological Sciences." Ecological Applications 7(1): 330-242.
PURL (1998). Dublin Core Metadata. http://dublincore.org/.
Resource Description Framework efforts (1998), http://www.w3.org/RDF
Weibel, S. (1998). Dublin Core Metadata. http://dublincore.org/
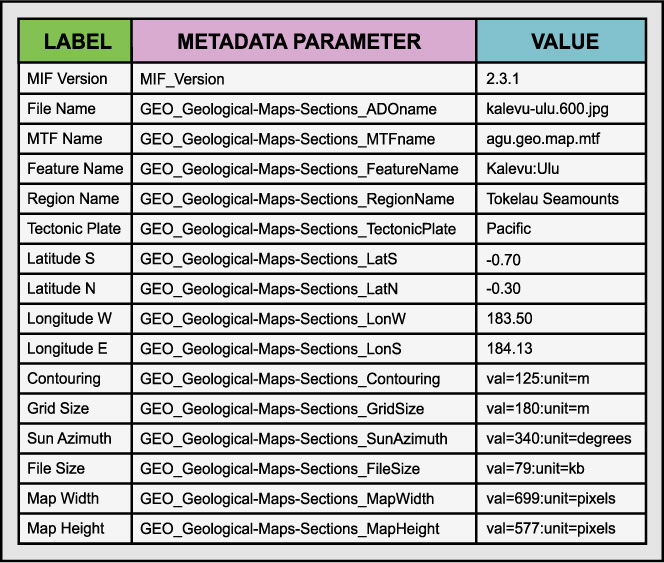
Appendix A. Map data example
This appendix depicts a set of metadata parameter that are useful for map images that are also treated as ADOs. The image file is the ADO in this case.